The team projects were a team effort. The team consisted by: Leigh, F., Van Toor, A., Koilakos, P.
All industrial revolutions share the fact that they resulted in tremendous changes in people's lives and global economies. Moreover, starting from the first industrial revolution (use of coal) to the ongoing fourth industrial revolution (internet and renewable energy), it is apparent that the duration of those revolutions has been decreasing from one to another (Upkeep, no date).
However, their long-lasting effects paved the road for the subsequent industrial revolutions.
The ongoing fourth industrial revolution progresses exponentially (Schwab, 2016), and it still needs to be determined when it will conclude.
The exponential growth rate translates to exponential benefits for humanity, but that comes with risks due to potential systems' failures.
One such failure, revolving around the big data area of revolution 4.0, occurred early in the revolution's period (before 2014,
when the term revolution 4.0 was nearly non-existent) (McKinsey & Company, 2022), with the Google Flu Trends (GFT), a program aiming at nowcasting flu's prevalence based on people's
used search terms in Google search. Google was aiming to be able to forecast such an outbreak two weeks earlier than the US Centre for Disease Control and Prevention (CDC).
The programme miss-forecasted the flu outbreak by 140 per cent, with the information system subsequently being discontinued (Lazer & Kennedy, 2015).
According to The Guardian (2014), the main points of failure have been the lack of continuous code-tweaking based on experience, miss-interpreting searches,
and mistakenly connecting them with flu-related incidents (e.g. the term 'fever' is not necessarily connected with the flu), the simultaneous roll-out of the autosuggest
feature which may mislead Google's users in using flu-related terms and the fact that correlation analysis turned into a causation analysis. One of the critical points of failure,
valid for all big-data projects, is that some areas can only be accurately analyzed with prior experience.
In a nutshell, while the opportunities of revolution 4.0 are nowadays clear and significant steps have been made for the efficient use of related technologies which
will leverage its benefits for humanity, it is equally essential to be reminded about the risks of errors due to negligence which may result in taking wrong decisions affecting people's
lives (e.g. limitation in freedom of movement) and global economies.
Artificial Intelligence (AI) as a concept is considered by many to have its roots in the mid-1950s, when, during the Dartmouth Summer
Research Project on Artificial Intelligence, a program that could mimic humans in problem-solving was presented (Anyoha, 2017). However, Artificial Intelligence
is considered a new term for the general public, which was introduced in our lives mainly with the groundbreaking release of GPT-3. Thus, the public is puzzled when
discussing the benefits and risks of such technology, with 37% of Americans being more concerned than excited, 18% being more excited than concerned, and the remaining
45% being equally concerned and excited (Rainie et al., 2022).
Since the boom of AI, many risks have been identified and are re-iterated by many.
These include the lack of transparency (black box), induced bias and discrimination, security,
ethical and privacy concerns, misinformation and legal and regulatory risks (Marr, 2023). Starting
with the lack of transparency, AI models such as GPT-3 and Microsoft's AI have refused to release their code or
training data, failing to provide insight into their code's mechanisms, thus lacking transparency (Hutson, 2021). Moreover,
with the 'right to privacy' being introduced increasingly in our daily lives, the limited transparency on AI, the lack of AI-specific security requirements,
and legislative & regulatory gaps, mainly deriving from the demanding and time-consuming policy-making process, may put people's right to secrecy and online security at risk
(Jia & Zhang, 2020; Perru & Uuk, 2019). Furthermore, bias and discrimination have been considered interconnected in the AI field. Bias and discrimination are often found in AI
models and they revolve around religion, gender and ethnicity and race (Hutson, 2021).
Despite the negative aspects of AI technology, one cannot look the other way at the significant benefits that such technology already has and has the potential to introduce.
AI has already found many applications in finance, medicine, and sciences. Those fields can all benefit from AI applications such as automation, smart decision-making, research and
error reduction (Western Governors University, 2022). Many already benefit from finance-related AI applications like fraud detection and portfolio management. Other finance-related
AI applications involve automation, such as targeted financial recommendations, or efficiency improvement components, such as AI bots (Google, 2023). AI is also widely used in medicine
with automated tracing for high-risk patients, improvements in diagnosis speed and accuracy and finally by enhancing efficiency and thus allowing wider access to health care by allowing
professionals to work faster, without any tradeoff in accuracy and being able to reach more patients in a given day (Moore, 2023). AI involvement in sciences arguably provides long-term
advantages to people worldwide. Laboratory processes such as hypothesis and analysis can be significantly sped up, outcomes analysis can be automated and related literature and research
can be located within seconds (Data Science UA, N.D.).
To summarize, the current advantages of AI and the potential enhancements in the years to come make such technology necessary for several disciplines.
Though, the leverage of AI does not come without related risks. Several improvements must take place to ultimately shift the public's opinion from negative or
neutral to positive. These include the establishment of regulatory frameworks and technical measures that improve transparency, security, and one's right to privacy,
as well as steps to reduce and eliminate bias and discrimination. We may reach a point in time where we need to decide and differentiate between AIs that act as 'brainless mouths'
and AIs that act and behave as 'the people'.
In summary, technological advancements such as Artificial Intelligence (AI)
and Machine Learning (ML) have been increasingly rapid in recent years. Experts estimate that there is
a 90% chance that human-level artificial intelligence will exist sometime in the next 100 years (Roser, 2023).
With the AI market expected to reach 407 billion by 2027 (Haan & Watts, 2023), it is apparent that both concepts,
their present applications, as well as the constantly developing proof-of-concept for evolving applications,
will bring value and change in the global economies from the Finance discipline all the way to Healtcare,
and at the same time improve people's lives. At the same time, such applications should consider the present
risks and limitations carefully. Despite the size of the AI field, the applicable regulatory framework is
sparse, at best, with the EU adopting a proposal on AI liability only in late 2022 (European Commission, 2022).
Moreover, potential errors in the usage, coding or interpretation of the outcomes of such technologies
can pose a significant danger to people's rights, with two examples being the misestimation of flu's development
by 140% by Google (The Guardian, 2014) and the ongoing discussions on the defamation lawsuits against
OpenAI (Cahill, 2023). Finally, AI applications have been previously accused of discrimination and bias,
mainly related to religion, gender, ethnicity, and race (Ohlheiser, 2023). Even though there are significant
benefits to be gained through AI, there are also risks and challenges that need to be addressed. Balancing
the equities and achieving a balance between leveraging technology for positive outcomes and mitigating
potential negative consequences is more crucial than ever and is expected to be even more crucial in the
years to come.
Abstract
This report has identified a distinct area of potential increased revenue for Airbnb in New York, namely Queens. This was managed through data analysis and applying machine learning techniques such as clustering.
The recommendations are therefore that Airbnb invests its resources there with a particular focus on ‘Entire home/apt’ listings due to the promising returns these types of listings can offer, leading to a considerable increase in revenue.
Finally, to gain a deeper understanding of the differences between these neighbourhoods, Airbnb can pay attention to answering the following question: Why is Queens currently relatively underpopulated in terms of Airbnb?
Abstract
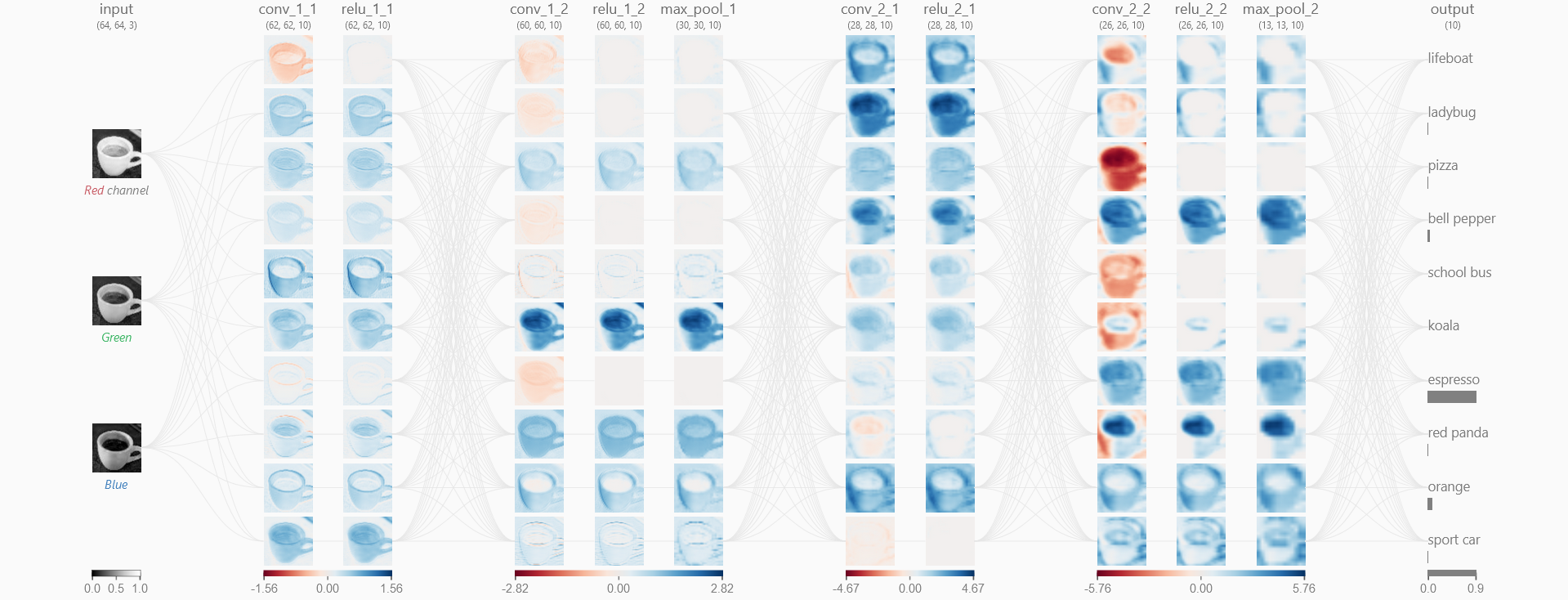
We were really pleased to get an accuracy score of 82.44% against the validation set after 39 epochs,
with a loss of 0.53. The loss and accuracy charts show a clear levelling-off but no marked downturn in performance.
Most importantly, when the model was finally tested on the unseen test data set it achieved an accuracy score of 82.08%,
so it was performing very consistently. The confusion matrix of the test results shows how well
it matched each class individually. We can see that most classes scored very well, with ship being the best.
The worst by some margin was cat, which was incorrectly matched with dog more than any other class.
Both team exercises were very beneficial for personal development purposes.
The exercises build on business analysis, Exploratory Data Analysis (EDA) to support the identified
business question and technical knowledge while supporting those above by respective reports and teamwork.
Generally speaking, business analysis supports organisations in connecting the management and technical
layers in order to bring improvement. Both projects concentrated on identifying business problems by analysing
the needs and later determining solutions to those problems.
Moreover, the business analysis had to be coupled with EDA and supported by a more
extensive EDA to visualise, summarise and interpret the given information. EDA also supported
in data cleansing, better understanding the data's characteristics and contents, and verifying or rejecting assumptions.
Additionally, both exercises' technical components were needed to
support and conclude the findings. Code was used to cleanse, present and analyse
data, identify patterns, create machine learning models, and ultimately make data-informed decisions.
Finally, the team format of those projects helped us develop and exercise several
skills essential for academic success and real-life professional environments. Skills such
as knowledge sharing, time and workload management, and self-reflection are invaluable in
promoting mutual learning and contributing to personal development.
To summarise, both team exercises allowed us to understand the suitability
and applicability of our theoretical knowledge while implementing and evaluating
our technical implementations to practical scenarios, topped up with the teamwork
component that gave us the valuable opportunity to practise, develop and utilise the skills
that are required to be an influential member of a team.
Reflecting on completing this machine learning module, I feel like
I have gained a significant range and depth of knowledge and skills from the theoretical as
well as the practical and technical components of this module.
Starting with the theoretical components, I have studied and gained an understanding of
machine learning's core algorithms and their mathematical foundations. Such knowledge is necessary
to comprehend why we do certain things, apart from performing the tasks mindlessly. Complementary
to that, I was exposed to data analytics, and I got to understand the role of data in developing machine learning models.
The module knowledge was not isolated to a theoretical understanding, and the experience of applying
machine-learning techniques to real-world problems through the module's several requirements for project
implementation was a key takeaway for me. Throughout the module, I had the opportunity to actively use
Python in real-world data, which was an invaluable experience and helped me bridge the gap between theory
and practice, which is my primary learning outcome goal.
Moreover, through the theoretical understanding and hands-on practice,
I realised the relevance and applicability of machine learning in addressing
complex problems and its usage potential across numerous sectors, as well as in an interdisciplinary context.
Throughout this module, broader considerations involved in machine learning were also discussed. I learned to
research, describe and consider the legal, social, ethical, and professional issues that can arise in the machine
learning field during project implementation. It was also particularly insightful to explore the applicability and
challenges associated with different datasets and understand how these factors can influence the effectiveness of
machine learning algorithms.
Finally, the module offered experience-gain in team dynamics and teamwork through team exercises.
It enhanced my ability to function effectively and efficiently as part of a web-based team, giving me insights
into the importance of collaboration and communication in achieving shared organisational goals.
Notwithstanding the valuable knowledge I gained, I realised that further study of the field would be needed to
achieve sufficient expertise. Further experience-gaining will boost my confidence while applying the acquired
knowledge in real-life applications.
In conclusion, this module has equipped me with a vital understanding of machine learning and helped
me gain practical data analytics skills while acquiring awareness of the broader issues surrounding machine
learning applications. Reflecting on my learning journey, I feel well-prepared to broaden my knowledge with
more complex concepts and hopefully apply these skills and knowledge in my day-to-day work.