
My name is Panagiotis Koilakos, studying the module Research Methods and Professional Practice,
delivered by the University of Essex Online and presenting hereby a Research Proposal Presentation. The subject of our
research proposal (project title) is "Queuing Theory in Practice: Employing and Applying Queuing Theory for Humanitarian
Registration and Assistance Delivery Activities", attempting to link the realm of queuing theory with computing
models and applications and the humanitarian sector in order to better assist people in need. The overall aim
is to achieve this as part of the capstone project/dissertation of the Master of Science in Data Science
delivered by the University of Essex.

The contents of the presentation and their aim are the following:
1. The Value Delivery Section, where we attempt to link the subject with the potential value provided in the
subject of Computing and Data Science, along with explaining the research problem which we are trying to resolve;
2. The Research Question Section, where we will dive more in-depth into the underlying research questions of the
subject as mentioned earlier;
3. The Aims and Objectives Section, where we will describe our aims and objectives, which will later determine
the success of the project;
4. The Key Literature Section, where we will provide some insight into the available literature for all the parts
of the interdisciplinary matter at hand;

The presentation will resume with the following:
5. The Methodology Section, where our approach will be discussed, both from a theoretical perspective
(literature review) as well as an application perspective (computing and coding), linking the contents with
the BCS Project Requirements as provided by the University of Essex (2022);
6. The Ethical Considerations and Risk Assessment Section, where we will unfold the ethical considerations
and associated risks of the proposed subject both from a computing perspective and a personal perspective.
The proposed Research risk assessment resources of the University of Essex (N.D.) will also be used;
7. The Artefacts Section, where we will propose the deliverables of our research;
8. The Timeline Section, where we will leverage the power of Gannt Charts (Clark et al., 1922) to present
the proposed sequence of events, milestones and deadlines; and,
9. The References Section.

At its core and in an oversimplified explanation, queuing theory discusses waiting lines and
seeks to explain the complex dynamics of queues, from how they form and evolve to how they dissipate (University
of Idaho, N.D.).
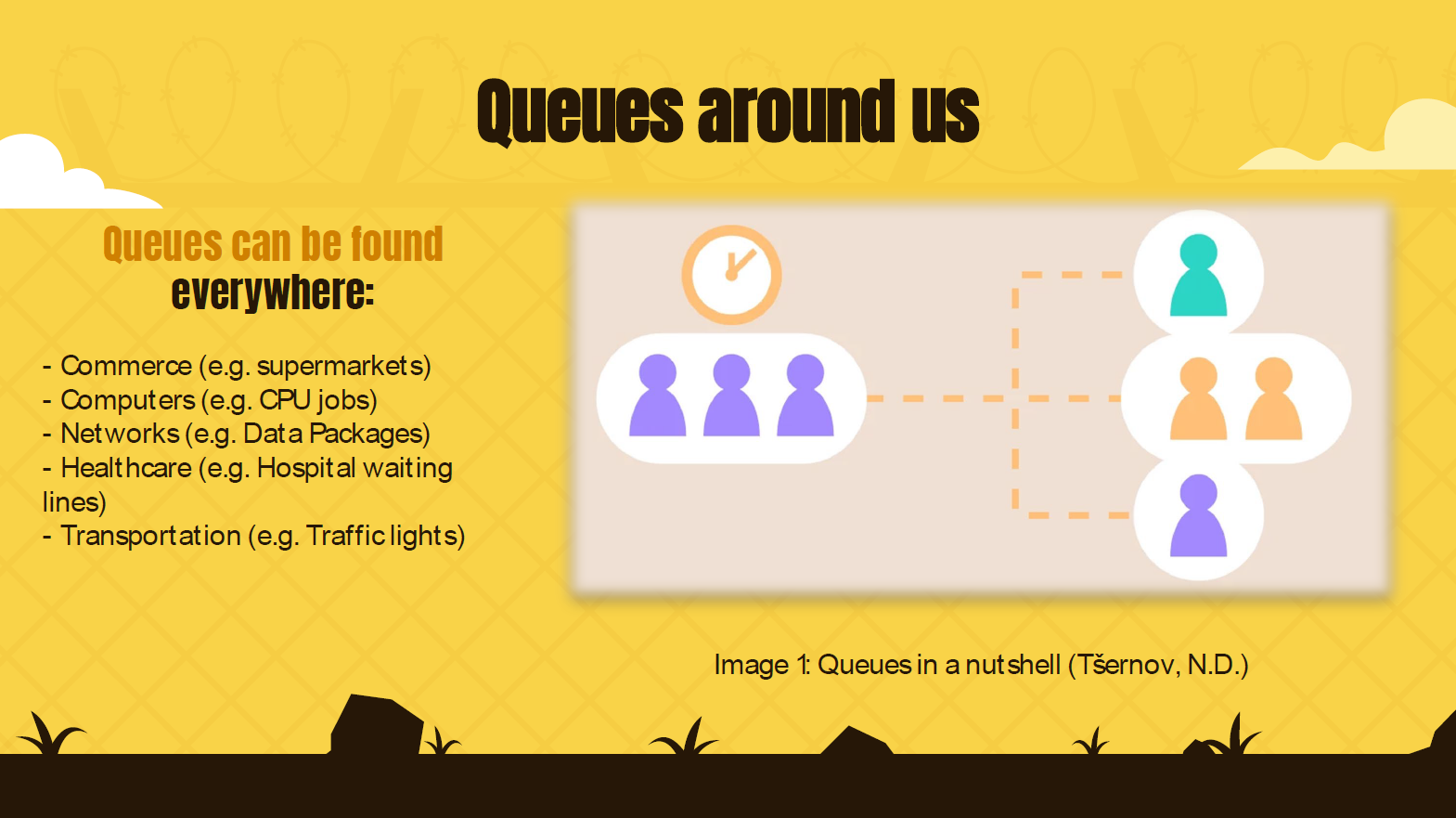
From a simplistic to a complex implementation, queuing can be found everywhere around us,
from grocery stores and supermarkets to traffic flow and computer systems. In computing, queues can be found
in components such as networks (for example, data packages transmitted over the internet) or processors
(for example, how a CPU handles incoming jobs) (Ralston et al., 2000).
Besides utilising queues, computing systems can help researchers analyse queues to solve everyday problems.
Queuing models leveraging computers are also used in traffic control
(University of Idaho, N.D.), healthcare and critical care (Fomundam et al., 2007; McManus et al., 2004) as well as
in emergency services (Joseph, 2020).

Following a similar approach, our research proposal aims to understand how queues work in other
disciplines, how computing can provide value in the utilisation and optimisation of queues, and how queues can be used
in humanitarian contexts in complex environments for registration and assistance delivery activities.
By answering this subset of questions, we aim to showcase how the widely used concept of queues can use the computing
and data analysis disciplines to assist the humanitarian field with the problem of reducing waiting times for
populations in perilous situations and apply proper prioritisation by using the technology and computing concepts
in a reproducible and usable manner. This technological intervention can potentially assist more than 108 million
displaced people worldwide (UNHCR, 2023).

The development of the research question followed the following thought process:
- Locating a generic topic based on professional and educational experience;
- Conducting research on the topic by discussing with subject matter experts but also based on work experience and
relevant literature;
- Considering 'who is interested in this topic', mainly focusing on academia and international organisations;
- Contemplating on the questions that can be asked for the topic, starting from broad questions and making them
more specific along the way, and,
- Finally, evaluate the asked question in terms of relevance to the computer field, available literature,
research gap, estimated general interest, clarity and complexity (George Mason University, 2018;
Monash University, N.D.).

Following the process mentioned above, the proposed dissertation subject was narrowed down
to "Queuing Theory in Practice: Employing and Applying Queuing Theory for Humanitarian Registration and Assistance
Delivery Activities", which revolves around the central question of "How can the application of queuing theory
via computing systems enhance and optimise registration and assistance delivery activities in the humanitarian
field". Several other underlying questions exist, such as social consideration regarding the population of
concern or ethical consideration and upholding the principle of no harm; those will be partially discussed
at a later stage of this presentation (UNHCR, 2019).
The aim of our dissertation is directly linked to the research problem and the research
questions raised before. The research aim can be summarized in a few words as "understanding and presenting how queuing
works and applies in registration activities". Considering that this is a generic statement, the aim can be
further enhanced by diving deeper into the matter at hand. Understanding the role of queues and their importance
in humanitarian registration and assistance provision activities is a subject which has yet to be researched in
depth, judging by the available literature. Gaining an understanding, researching and presenting how queues work,
the different theorems, their applicability in humanitarian registration and assistance provision activities,
how they are affected by the specific realm of where they are applied, and the specific needs of the
population of concern is one of the primary aims of the dissertation.
Additionally, the research presents several opportunities through which we identify the key objectives:
1. Explain queuing theory on a high level and how it works in real life by exploring relevant literature;
2. Investigate queuing theory usage and applications in relevant disciplines (such as healthcare);
3. Explain how registration and assistance delivery activities work in the humanitarian sector and how they
are linked with queuing theory;
4. Explore the peculiarity of the queuing theory and its effect on the studied population,
especially in linkage with the psychological situation, their specific needs and their place of habitual
residence (e.g. in refugee camps);
5. Determine how queuing theory can be leveraged in the studied context;
6. Present examples from subject matter experts in relation to challenges while queuing in the studied
context;
7. Apply the findings to develop a reproducible and usable application, either in terms of a
mathematical model or computing artefact;
8. Discuss relevant ethical and legal considerations, and,
9. Provide concrete and actionable recommendations on how humanitarians can leverage technology
and the expertise of computer scientists to improve queuing conditions and waiting lines.

We performed the primary identification of relevant literature review in silos, meaning that we
attempted to find papers and other sources on the topics of our concern in an attempt to connect them throughout
the research later. For each of the identified categories, we will mention at most four relevant papers.
Our research references will be enriched throughout the research process. The categories and relevant
literature that we identified are:
1. Queuing theory and queuing theorems - for example, the book "Probability, Statistics and Queuing Theory
with Computer Science Applications" (Allen, 1990);
2. Queuing theory in real life, such as the "The queuing theory application in bank service optimization"
paper (Xiao et al., 2010) and the "Survey of Queuing Theory Applications in Healthcare"
(Fomundam et al., 2007);
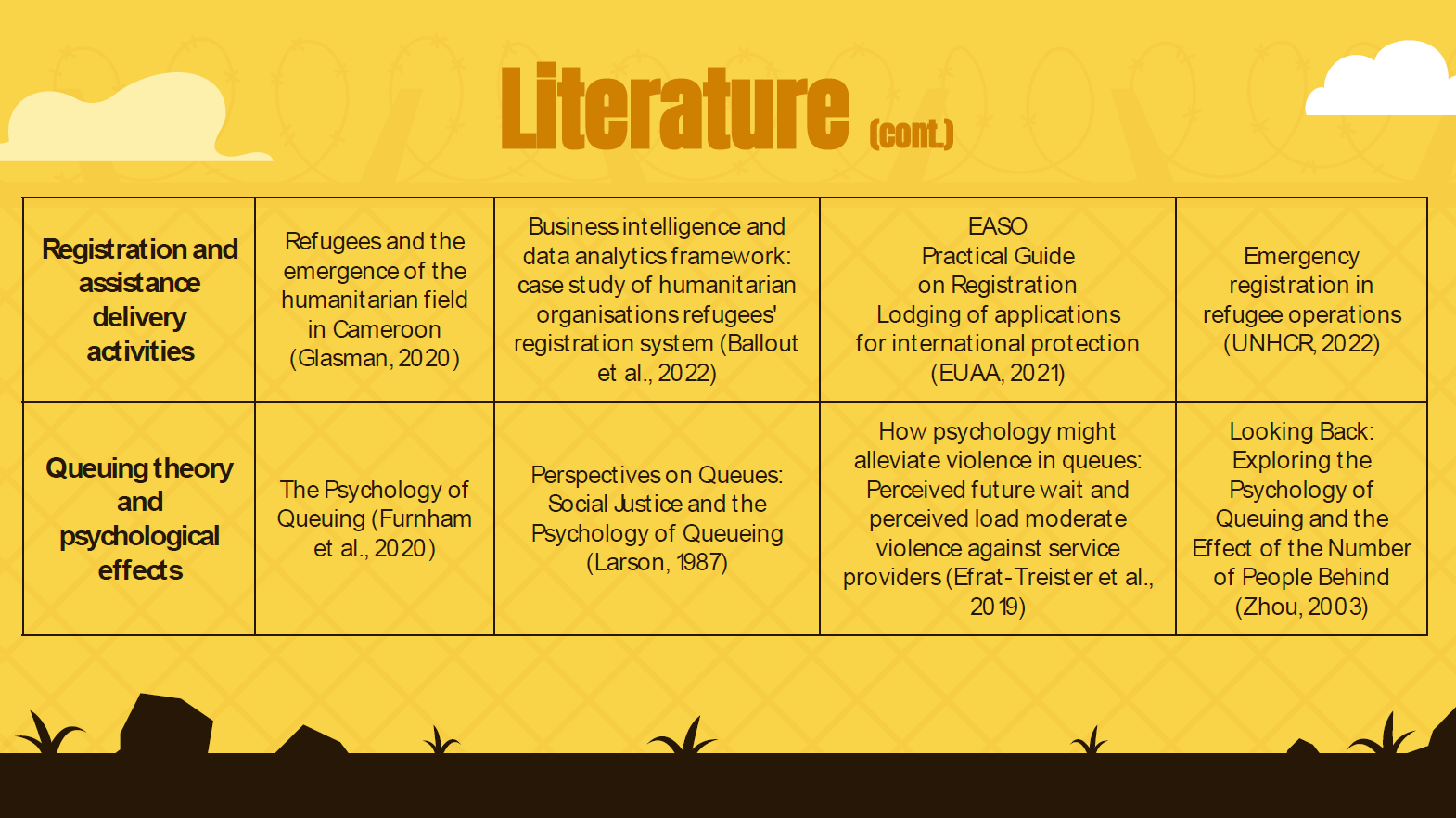
3. Registration and assistance delivery activities - for example, the Registration Chapter of the
book "Refugees and the emergence of the humanitarian field in Cameroon" (Glasman, 2020) and the
registration handbooks of different agencies (UNHCR, 2022; UNICEF, 2023; EUAA, 2021) ;
4. Queuing theory and psychological effects, such as the description in "The Psychology of Queuing"
(Furnham et al., 2020);

5. Queuing in humanitarian contexts, for example, the article "Queuing to leave: A new approach to immigration"
(Sarma, 2021);
6. Applied queuing theory through technology, such as the paper "Queue Length Estimation Using Connected
Vehicle Technology for Adaptive Signal Control" (Tiaprasert et al., 2015), and,

7. Queuing, computing and ethical considerations such as those described in the ACM
Code of Ethics and Professional Conduct (ACM, 2018);

The research will follow a mixed approach, combining both qualitative and quantitative
analysis. On a high level, the content of qualitative data will be analyzed both in terms of meaning and relevance
(direct or indirect), applying a combination of thematic analysis to identify trends and content analysis
particularly relevant to the literature review. On a qualitative approach, data (such as basic biodata
or queuing metrics) will be cleansed by ensuring no skewing in the underlying patterns,
and then business intelligence tools (such as PowerBI) will be used for the presentation part
(e.g. charts). In contrast, Python will be used to test queuing algorithms to provide a usable application.

Ethical considerations are paramount through the research considering the population of concern.
Primary ethical concerns will be identified through relevant literature and professional standards, such as the IASC
Code of Conduct (IASC, N.D.), governing humanitarian professionals or the ACM Code of Ethics and Professional
Conduct (ACM, 2018). The principle of do not harm (UNHCR, 2019) will be the governing compass on whether something
is ethical or not. At the same time, due to the nature of the research, handling ethically sensitive data
and avoiding biases (Pannucci & Wilkins, 2010) are also substantial. Moreover, the ethical considerations
will be coupled with a relevant risk assessment, focusing on the negative impact of research actions on the
population of concern, especially in their legal and physical protection. Risks associated with the disclosure
of sensitive information will be at the forefront, and thus, the research should leverage the power of peer
review to ensure that such risks are mitigated. To provide a thorough risk assessment, the toolkit provided
by the University of Essex (University of Essex, N.D.) will be used.

On the research deliverables, we aim to develop three artefacts. The primary artefact,
which should also serve as a stand-alone document, will be the research report, where research questions,
data analysis, code writing, and subject-matter expertise will be combined to conclude on actionable recommendations.
The annexes will accompany the report and serve as metadata to verify the research methodology and outcomes
and enable researchers to develop the research further. Finally, as the application/hands-on deliverable
required by the BCS Project Requirements (University of Essex, 2022), we aim to deliver a working
application/algorithm, utilising the identified queuing methodology, providing value to humanitarians on
the field.
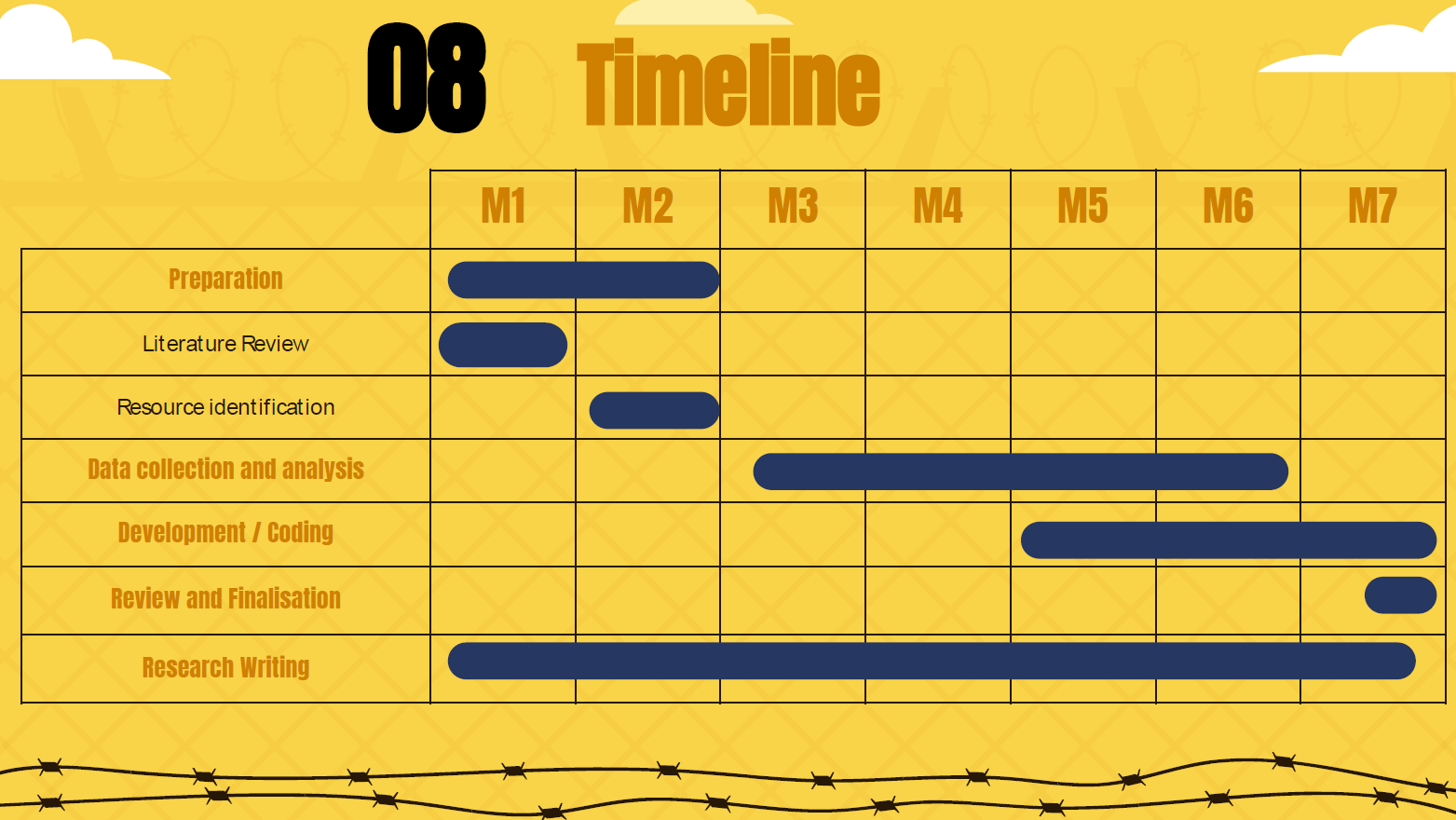
A high-level timeline and sequence of events has been created to show the main steps of the
process. The period has been broken down into seven months (M1 to M7), starting from the Preparation stage (M1 to M2),
where the literature will be collected, reviewed, and assessed in regards to relevance and usability (M1),
and resources, such as subject matter experts and relevant data will be identified (M2). From a business intelligence
and infographics perspective, data collection and analysis will follow the collection of resources throughout
M3 to M6. Considering the need for an application deliverable, this will be developed throughout M5 to M7,
while the products will be reviewed as a whole during the last half of M7. The research writing,
which will produce the primary artefact as presented earlier, will continue throughout the whole period
(M1 to M7) by collecting and writing down ideas and exciting approaches to later form, through the steps
above, the final product.